Я использовал Линейный Дискриминантный Анализ (LDA) из scikit-learnбиблиотеки машинного обучения (Python) для уменьшения размерности, и мне было немного интересно узнать о результатах. Теперь мне интересно, что scikit-learnделает LDA , чтобы результаты выглядели иначе, чем, например, ручной подход или LDA, выполненные в R. Было бы здорово, если бы кто-то мог дать мне некоторое представление здесь.
Что в основном больше всего беспокоит то, что scikit-plotпоказывает корреляцию между двумя переменными, где должна быть корреляция 0.
Для теста я использовал набор данных Iris, и первые 2 линейных дискриминанта выглядели так:
IMG-1. LDA через scikit-Learn

Это в основном согласуется с результатами, которые я нашел в документации scikit-learn здесь.
Теперь, я прошел через LDA шаг за шагом и получил другой прогноз. Я попробовал разные подходы, чтобы выяснить, что происходит:
IMG-2. LDA на необработанных данных (без центрирования, без стандартизации)

И здесь был бы пошаговый подход, если бы я сначала стандартизировал (нормализация по z-шкале; дисперсия единиц). Я сделал то же самое только со средним центрированием, что должно привести к тому же относительному проекционному изображению (и это действительно так).
IMG-3. Пошаговое LDA после центрирования или стандартизации

IMG-4. LDA в R (настройки по умолчанию)
LDA в IMG-3, где я центрировал данные (что было бы предпочтительным подходом), выглядит также точно так же, как тот, который я нашел в Посте кем-то, кто делал LDA в R

Код для справки
Я не хотел вставлять здесь весь код, но я загрузил его как записную книжку IPython, разбитую на несколько шагов, которые я использовал (см. Ниже) для проекции LDA.
- Шаг 1: Вычисление d-мерных средних векторов
Шаг 2: Вычисление матриц рассеяния
2.1. Матрица рассеяния внутри класса вычисляется по следующему уравнению:
2.2 Матрица рассеяния между классами вычисляется по следующему уравнению: где - общее среднее.
Шаг 3. Решение обобщенной задачи на собственные значения для матрицы
3.1. Сортировка собственных векторов по убыванию собственных значений
3.2. Выбор k собственных векторов с наибольшим собственным значением. Объединение двух собственных векторов с наивысшими собственными значениями для построения нашей -мерной матрицы собственных векторов
Шаг 5: Преобразование выборок в новое подпространство


























источник
Ответы:
Обновление: благодаря этому обсуждению
scikit-learnбыл обновлен и теперь работает правильно. Его исходный код LDA можно найти здесь . Первоначальная проблема возникла из-за незначительной ошибки (см. Это обсуждение на github ), и мой ответ на самом деле не указывал на нее правильно (извинения за возникшую путаницу). Поскольку все это больше не имеет значения (ошибка исправлена), я отредактировал свой ответ, чтобы сосредоточиться на том, как LDA может быть решено с помощью SVD, который является алгоритмом по умолчанию вscikit-learn.После определения матриц рассеяния внутри и между классами и стандартный расчет LDA, как указано в вашем вопросе, состоит в том, чтобы взять собственные векторы в качестве дискриминантных осей ( см., например, здесь ). Однако те же оси можно вычислить немного по-другому, используя отбеливающую матрицу:





Вычислить . Это отбеливающая трансформация по отношению к объединенной ковариации внутри класса (подробности см. В моем связанном ответе).




Обратите внимание, что если у вас есть собственное разложение , то . Также обратите внимание, что можно вычислить то же самое, выполнив SVD для объединенных данных класса: .



































Найдите собственные векторы , назовем их .




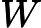

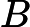





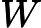


Опять же, обратите внимание, что его можно вычислить, выполнив SVD данных между классами , преобразованных с помощью , то есть данных между классами, отбеленных по отношению к классу внутри класса. ковариации.
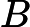





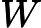
Оси дискриминанта будут заданы как , то есть главными осями преобразованных данных, преобразованных снова .





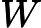


Действительно, если является собственным вектором указанной матрицы, то и умножение слева на и определение , мы сразу получаем :

Таким образом, LDA эквивалентно отбеливанию матрицы средних классов в отношении ковариации внутри класса, выполнению PCA на средних классах и обратному преобразованию результирующих главных осей в исходное (неотбеленное) пространство.
На это указывает, например, «Элементы статистического обучения» , раздел 4.3.3. В
scikit-learnэто путь по умолчанию для вычисления LDA , потому что SVD матрицы данных численно более стабильны , чем о собственных разложении его ковариационной матрицы.Обратите внимание, что вместо можно использовать любое отбеливающее преобразование, и все будет работать точно так же. В (вместо ) и это работает просто отлично (вопреки тому, что изначально было написано в моем ответе).




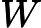









scikit-learnисточник
Чтобы закрыть этот вопрос, обсуждаемая проблема с LDA была исправлена в scikit-learn 0.15.2 .
источник