Я хотел бы ранжировать коллекцию пейзажных изображений, создав игру, в которой посетители сайта могут оценивать их, чтобы выяснить, какие изображения люди находят наиболее привлекательными.
Что было бы для этого хорошим методом?
- Горячий или нет стиль ? Т.е. покажите одно изображение, попросите пользователя оценить его от 1 до 10. На мой взгляд, это позволяет мне усреднить оценки, и мне просто нужно убедиться, что я получу равномерное распределение голосов по всем изображениям. Довольно просто реализовать.
- Выбрать А-Б ? Т.е. покажите два изображения, попросите пользователя выбрать лучшее. Это привлекательно, так как здесь нет числового рейтинга, это просто сравнение. Но как мне это реализовать? Моя первая мысль заключалась в том, чтобы сделать это как быструю сортировку, с операциями сравнения, выполняемыми людьми, и после завершения просто повторить сортировку до бесконечности.
Как бы ты это сделал?
Если вам нужны числа, я говорю об одном миллионе изображений на сайте с 20 000 посещений в день. Я предполагаю, что небольшая часть может сыграть в эту игру, ради аргументации, допустим, я могу производить 2000 операций сортировки людей в день! Это некоммерческий сайт, и неизменно любопытные найдут его в моем профиле :)
algorithm
sorting
crowdsourcing
Пол Диксон
источник
источник
Ответы:
Как говорили другие, ранжирование от 1 до 10 не работает так хорошо, потому что люди имеют разные уровни.
Проблема с методом Pick A-or-B заключается в том, что не гарантируется транзитивность системы (A может превзойти B, но B превосходит C, а C лучше A). Наличие нетранзитивных операторов сравнения нарушает алгоритмы сортировки . В этом примере с быстрой сортировкой буквы, не выбранные в качестве опорных, будут неправильно сопоставлены друг с другом.
В любой момент времени вам нужен абсолютный рейтинг всех изображений (даже если некоторые / все из них связаны). Вы также хотите, чтобы ваш рейтинг не менялся, если кто-то не проголосует .
Я бы использовал метод Pick A-or-B (или ничью) , но определял бы рейтинг аналогично системе рейтингов Эло, которая используется для ранжирования в играх для двух игроков (первоначально шахматах):
Система Эло:
Замените «плееры» картинками, и у вас будет простой способ изменить рейтинг обоих изображений на основе формулы. Затем вы можете выполнить ранжирование, используя эти числовые оценки. (K-Value здесь - это «уровень» турнира. Он составляет 8–16 для небольших местных турниров и 24–32 для более крупных приглашенных / региональных турниров. Вы можете просто использовать константу, например 20).
С помощью этого метода вам нужно сохранить только одно число для каждого изображения, что намного меньше потребляет память, чем сохранение отдельных рангов каждого изображения для каждого изображения.
РЕДАКТИРОВАТЬ: добавлено еще немного мяса на основе комментариев.
источник
У большинства наивных подходов к проблеме есть несколько серьезных недостатков. Хуже всего то, как bash.org и qdb.us отображают котировки: пользователи могут проголосовать за котировку вверх (+1) или вниз (-1), а список лучших цитат отсортирован по общему нетто-баллу. Это страдает от ужасной предвзятости во времени - старые цитаты собрали огромное количество положительных голосов благодаря простому долголетию, даже если они лишь отчасти юмористические. Этот алгоритм мог бы иметь смысл, если бы шутки становились смешнее с возрастом, но - поверьте мне - это не так.
Существуют различные попытки исправить это - посмотреть количество положительных голосов за период времени, взвесить более свежие голоса, внедрить систему убывания для старых голосов, вычислить соотношение положительных и отрицательных голосов и т. Д. Большинство из них страдают другими недостатками.
Лучшее решение - я думаю - это то, что используют сайты The Funniest The Cutest , The Fairest и Best Thing - модифицированная система голосования Кондорсе :
Для получения дополнительной информации о внедрении таких систем посетите страницу Википедии о ранговых парах. будет полезна .
Алгоритм требует, чтобы люди сравнивали два объекта (ваш вариант Pick-A-or-B), но, честно говоря, это хорошо. Я считаю, что в теории принятия решений очень хорошо принято, что люди намного лучше сравнивают два объекта, чем при абстрактном ранжировании. Миллионы лет эволюции делают нас хорошими в том, чтобы сорвать лучшее яблоко с дерева, но ужасно в том, чтобы решить, насколько близко яблоко, которое мы сорвали, отрублено к истинной платонической форме яблони. (Это, кстати, то, почему процесс аналитической иерархии такой изящный ... но это уже немного не по теме.)
Наконец, следует отметить, что SO использует алгоритм для поиска наилучших ответов, который очень похож на алгоритм bash.org для поиска наилучшей цитаты. Здесь он работает хорошо, но там ужасно не работает - в значительной степени потому, что старый, высоко оцененный, но теперь устаревший ответ здесь, вероятно, будет отредактирован. bash.org не позволяет редактировать, и непонятно, как бы вы вообще отредактировали анекдоты десятилетней давности об устаревших интернет-мемах, даже если бы могли ... В любом случае, я считаю, что правильный алгоритм обычно зависит от деталей вашей проблемы. :-)
источник
Я знаю, что этот вопрос довольно старый, но я думал, что внесу свой вклад
Я бы посмотрел на систему TrueSkill, разработанную в Microsoft Research. Это похоже на ELO, но имеет гораздо более быстрое время сходимости (выглядит экспоненциально по сравнению с линейным), поэтому вы получаете больше от каждого голосования. Однако математически это сложнее.
http://en.wikipedia.org/wiki/TrueSkill
источник
Мне не нравится стиль Hot-or-Not . Разные люди выбирали бы разные числа, даже если бы изображение им всем нравилось одинаково. Также я ненавижу оценивать вещи из 10, я никогда не знаю, какой номер выбрать.
Выбрать A-or-B намного проще и веселее. Вы увидите два изображения, и они будут сравнивать изображения на сайте.
источник
Эти уравнения из Википедии упрощают / повышают эффективность расчета рейтингов Эло, алгоритм для изображений A и B будет простым:
Рассчитайте новые рейтинги для обоих, используя: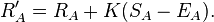
Обновите новые рейтинги RA, RB и количество mA, mB в базе данных.
источник
Вы можете использовать комбинацию.
Первый этап: стиль «Горячо или нет» (хотя я бы выбрал 3 варианта: отстой, Мех / ОК. Круто!)
После того, как вы разложили набор по 3 сегментам, я бы выбрал два изображения из одного сегмента и выбрал вариант «Что лучше».
Затем вы можете использовать английскую футбольную систему повышения и понижения, чтобы переместить несколько лучших «отстойных» в область Meh / OK, чтобы уточнить крайние случаи.
источник
Рейтинг 1-10 не подойдет, у всех разные уровни. Тот, кто всегда ставит 3-7 оценок, затмевает его рейтинг людьми, которые всегда ставят 1 или 10.
a-or-b более работоспособен.
источник
Вау, я опаздываю в игре.
Мне очень нравится система ELO, но, как говорит Оуэн, мне кажется, что вы будете медленно добиваться каких-либо значительных результатов.
Я считаю, что у людей гораздо больше возможностей, чем просто сравнение двух изображений, но вы хотите свести взаимодействие к минимуму.
Итак, как насчет того, чтобы вы показывали n изображений (n - любое число, которое вы можете визуально отобразить на экране, это может быть 10, 20, 30, возможно, в зависимости от предпочтений пользователя) и заставить их выбрать, что они считают лучшим в этой партии. А теперь вернемся к ELO. Вам нужно изменить свою систему рейтингов, но сохранить тот же дух. Фактически, вы сравнили одно изображение с n-1 другими. Таким образом, вы делаете свой рейтинг ELO n-1 раз, но вы должны разделить изменение рейтинга на n-1, чтобы соответствовать (чтобы результаты с разными значениями n согласовывались друг с другом).
Готово. Теперь у вас есть лучшее из миров. Простая рейтинговая система, работающая со многими изображениями в один клик.
источник
Если вы предпочитаете использовать стратегию выбора A или B, я бы порекомендовал этот документ: http://research.microsoft.com/en-us/um/people/horvitz/crowd_pairwise.pdf
В статье рассказывается о модели Crowd-BT, которая расширяет знаменитую модель парных сравнений Брэдли-Терри на настройку краудсорсинга. Он также предоставляет алгоритм адаптивного обучения для повышения эффективности модели во времени и пространстве. Вы можете найти реализацию алгоритма в Matlab на Github (но я не уверен, что это работает).
источник
Несуществующий веб-сайт whatsbetter.com использовал метод стиля Эло . Вы можете прочитать об этом методе в их FAQ в Интернет-архиве .
источник
Выберите A-or-B, это самый простой и менее подверженный предвзятости, однако при каждом взаимодействии с людьми он дает вам значительно меньше информации. Я думаю, что из-за уменьшения предвзятости Pick превосходит и в определенных пределах предоставляет вам ту же информацию.
Очень простая схема подсчета очков - подсчитывать каждую картинку. Когда кто-то дает положительное сравнение, увеличивает счет, когда кто-то дает отрицательное сравнение, уменьшает счет.
Сортировка списка из 1 миллиона целых чисел выполняется очень быстро и на современном компьютере занимает меньше секунды.
Тем не менее, проблема довольно некорректна - вам понадобится 50 дней, чтобы показать каждое изображение только один раз.
Готов поспорить, хотя вас больше интересуют изображения с самым высоким рейтингом? Таким образом, вы, вероятно, захотите смещать поиск изображений в соответствии с прогнозируемым рангом - так вы с большей вероятностью будете показывать изображения, которые уже получили несколько положительных сравнений. Так вы быстрее начнете показывать «интересные» изображения.
источник
Мне нравится вариант быстрой сортировки, но я бы сделал несколько поправок:
Другой забавный вариант - использовать толпу для обучения нейронной сети.
источник